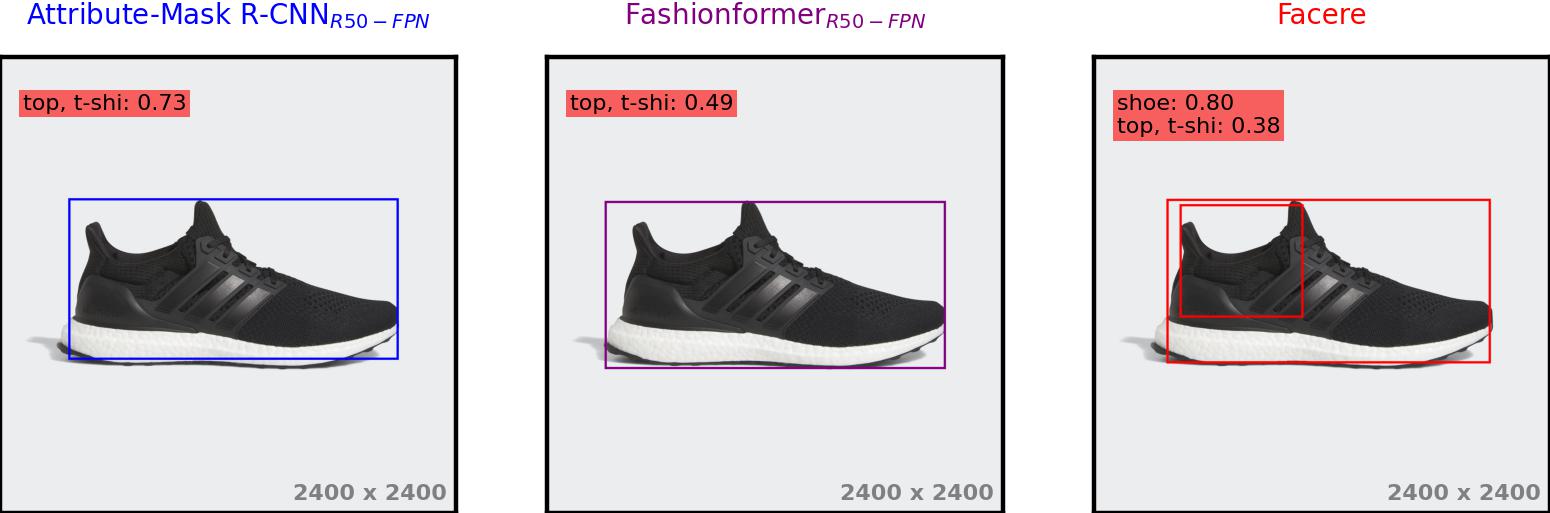
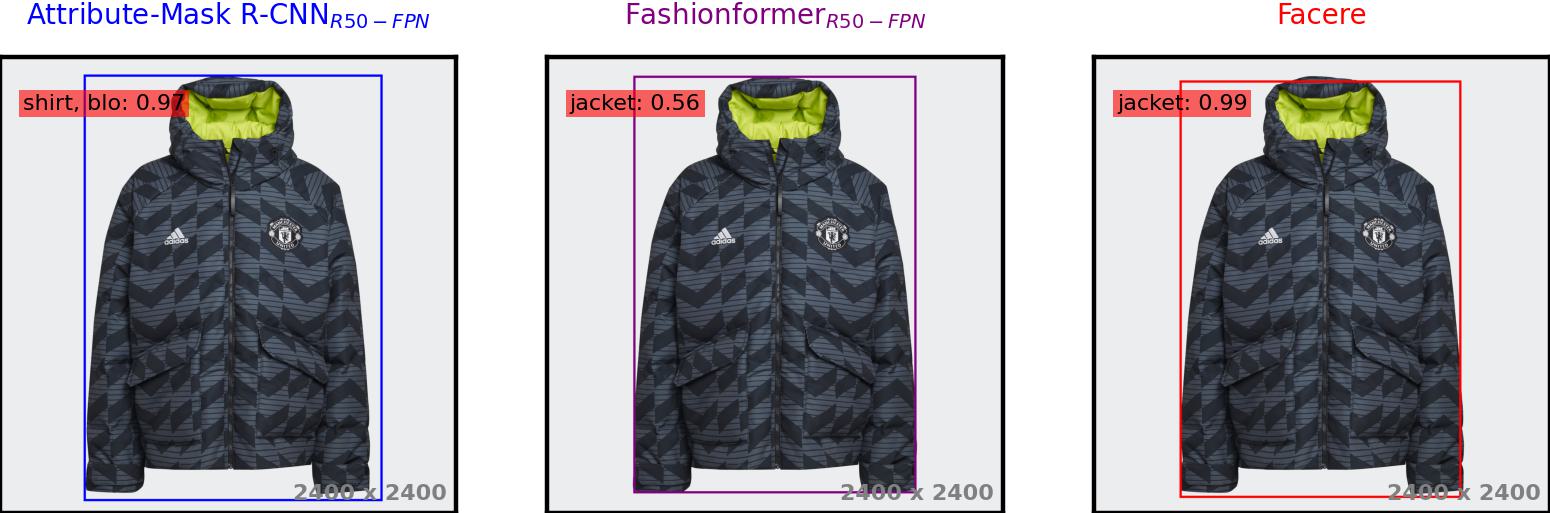
In the realm of fashion object detection and segmentation for online shopping images, existing state-of-the-art fashion parsing models encounter limitations, particularly when exposed to non-model-worn apparel and close-up shots. To address these failures, we introduce FashionFail; a new fashion dataset with e-commerce images for object detection and segmentation. The dataset is efficiently curated using our novel annotation tool that leverages recent foundation models.
The primary objective of FashionFail is to serve as a test bed for evaluating the robustness of models. Our analysis reveals the shortcomings of leading models, such as Attribute-Mask R-CNN and Fashionformer. Additionally, we propose a baseline approach using naive data augmentation to mitigate common failure cases and improve model robustness. Through this work, we aim to inspire and support further research in fashion item detection and segmentation for industrial applications.
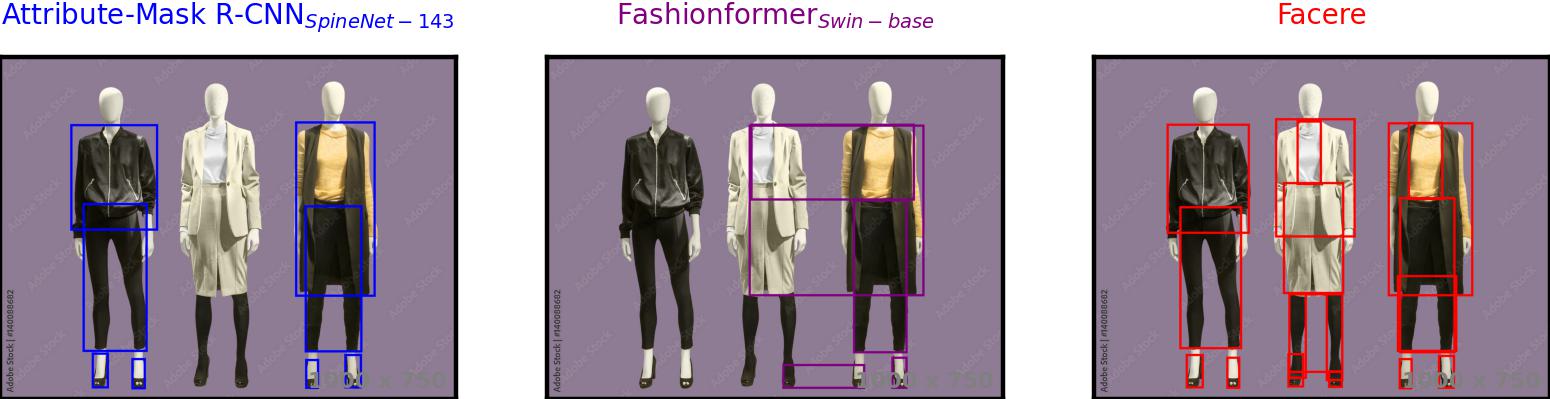
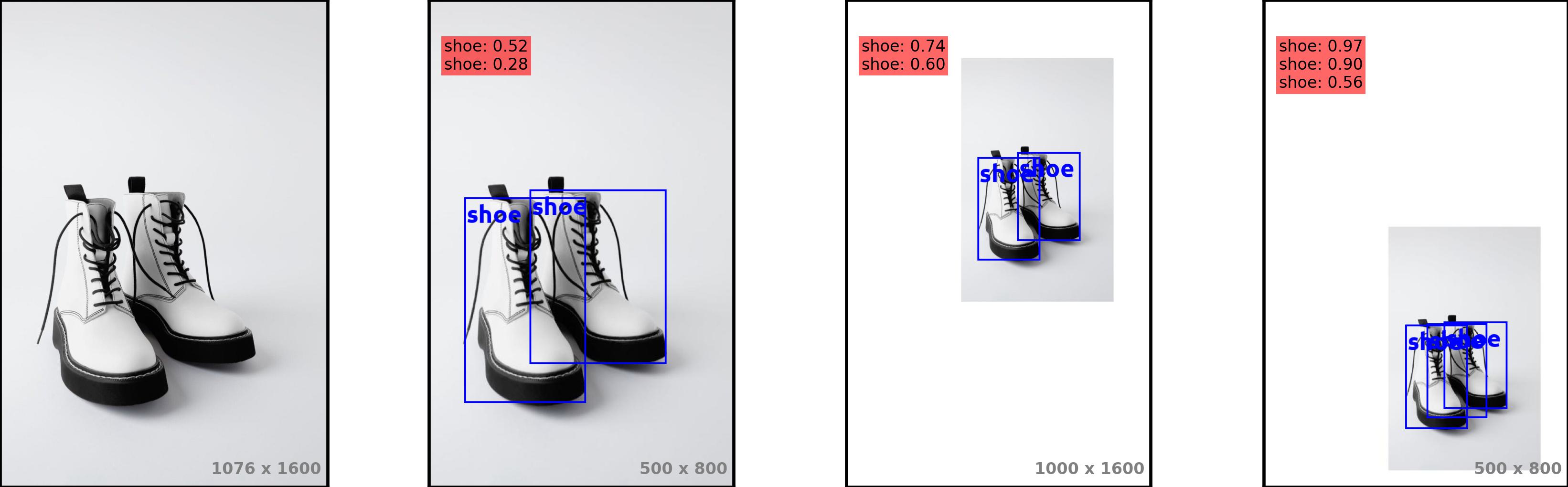
While Attribute-Mask R-CNN claimed that it "works reasonably well if the apparel item is worn by a model", pointing out the lack of context as the sole reason for these failures, our findings indicate that the issue is not solely due to the absence of context but also the scale of the items. In the original sizes of the images, Attribute-Mask R-CNNSpineNet-143 fails to detect displayed objects. However, simply rescaling images and/or zooming out (padding with white pixels) leads to correct detections:


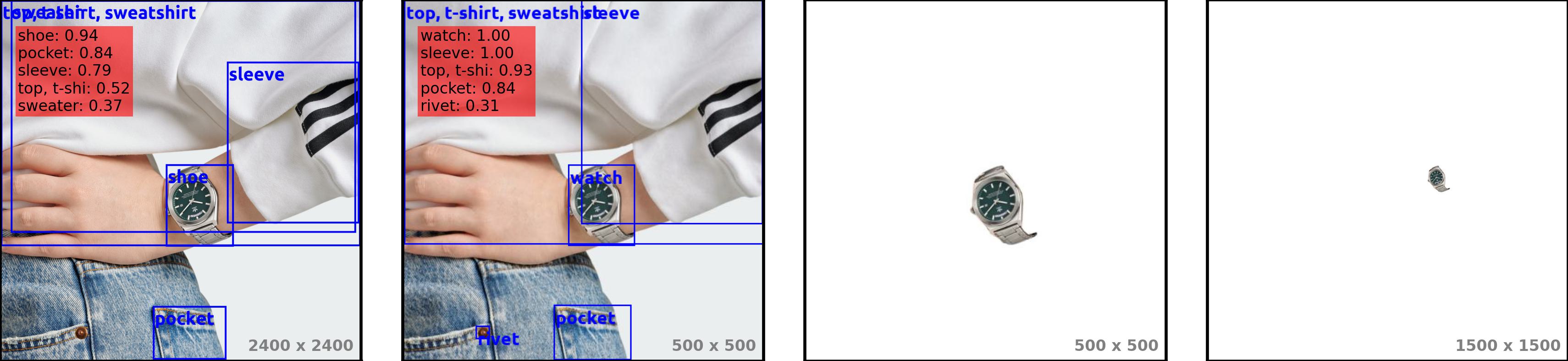
We demonstrate that scale alone may not be sufficient for detection in all cases and that both context and scale are required in some cases. For example, in the original size of an image, a 'watch' is detected as a 'shoe' with 94% confidence. Resizing the image already fixes the issue: the previously detected shoe becomes a watch with 100% confidence. However, removing the pixels not belonging to the watch leads to non-detection. Downsizing the image further does not resolve the issue:
By fine-tuning a pre-trained Mask R-CNN model on the Fashionpedia-train set using intelligent data augmentation techniques, we are able to address many of the failure cases. Furthermore, we improve the model performance (both bbox and mask mAP) on the Fashionfail-test dataset while matching the model performance of other baselines on Fashiopedia-val.
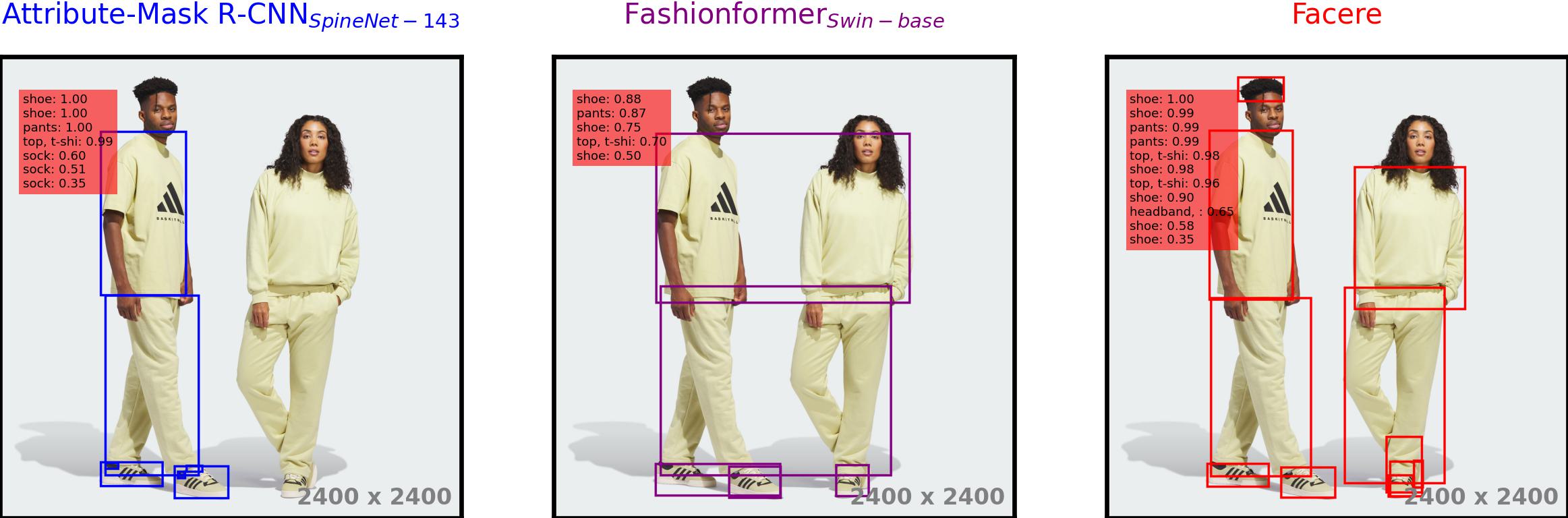
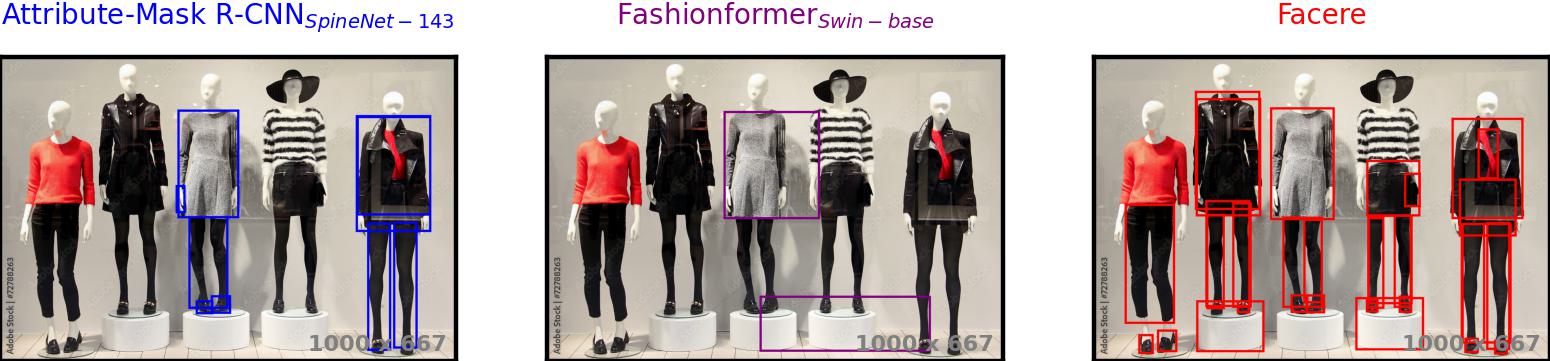
As a by-product of our method, we can also solve the multiple instance detection problem. Both baselines mostly
provide predictions for a single person, sometimes for the one in the foreground and sometimes for the one in the
background. Occasionally, they provide detections for both for some classes, while other times they merge boxes
unreasonably. This happens quite randomly. On the other hand, our model successfully provides accurate detections
thanks to our custom data augmentation method.
@inproceedings{velioglu2024fashionfail,
author = {Velioglu, Riza and Chan, Robin and Hammer, Barbara},
title = {FashionFail: Addressing Failure Cases in Fashion Object Detection and Segmentation},
booktitle = {IJCNN},
year = {2024},
doi = {https://doi.org/ng59},
eprint = {2404.08582}
}